免费评估

发送 10-20 篇代表性文献样本,我们演示结构化效果,为您量身定制数据转型方案。
解决方案打破数据孤岛,重塑课题组知识资产的生命力
高昂的人才培养成本随成员更替而流失。未结构化的历史实验记录、谱图与原始条件成为无法检索的“死数据”,造成严重的科研断层。
团队成员间缺乏共享的知识传承,导致重复查阅相同文献、重复验证已知反应。缺乏统一的知识沉淀,科研效率在低水平重复中损耗。
在数以千计的文件夹中手动翻找原文或笔记,不仅耗时费力,更会打断科研人员的深度思考流,让宝贵的灵感在繁琐的资料检索中消磨。
非结构化文本中隐藏着大量可转化、可放大的反应路线。由于缺乏智能挖掘手段,极具商业价值的科研成果往往被束之高阁,错失产业化先机。
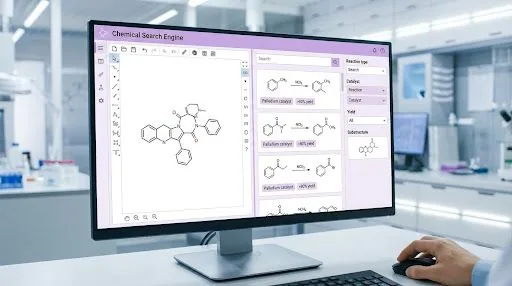
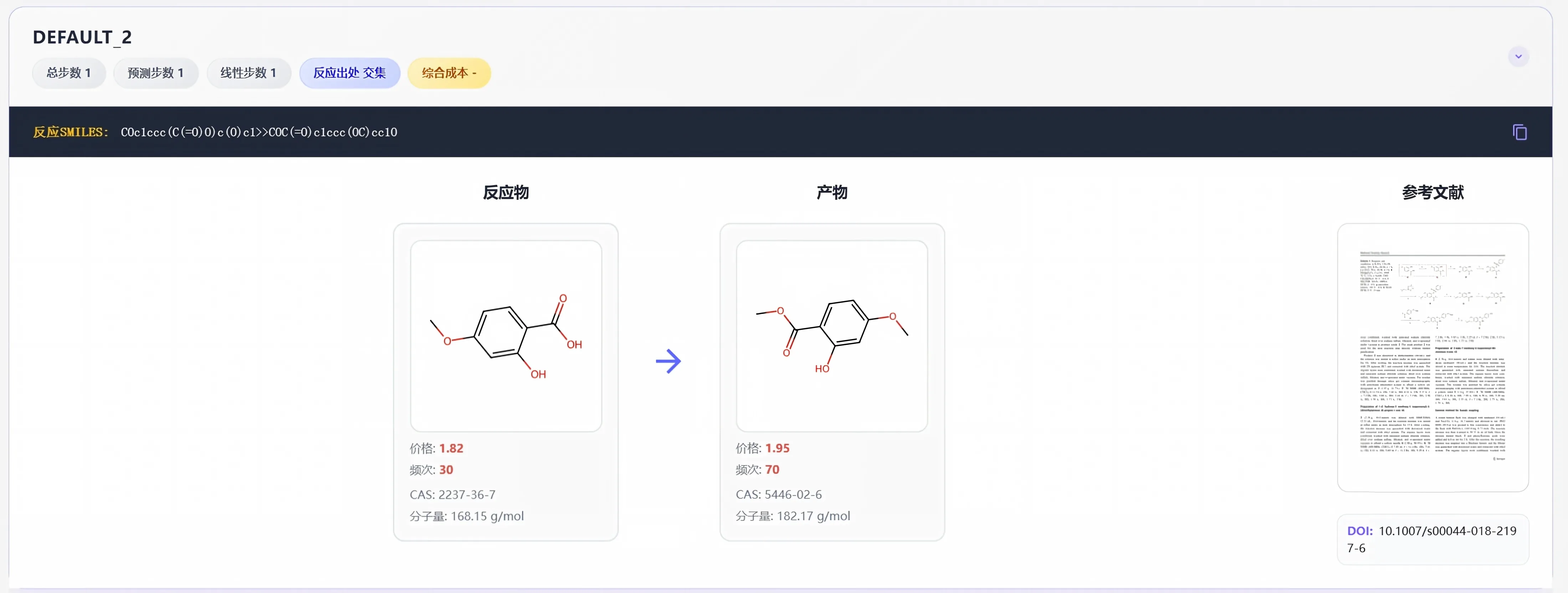
自动抽取反应式、底物结构、产率及精细条件,将碎片化记录转化为可检索、可分析的标准化数据库。
构建课题组专属知识图谱,支持结构式、关键词及反应类型多维检索,确保科研经验在团队中无缝流转。
从结构化条目直接跳转至 PDF 原文及精确标注位置,秒级定位参考反应,保持科研思维的连续性。
结合产业大数据引擎,自动识别具备放大潜力的反应路线,输出产业化候选方案,加速成果商业化进程。
采用 DeepExtract 专利 NLP 算法,化学实体识别准确率 >98%


有机合成、药物化学、材料化学、催化 课题组
研发部、工艺部、知识产权部
已有大量历史文献但“用不起来”的团队,激活沉睡数据,转化为科研资产
1 天熟悉组内全部历史工作,不再从零查文献。通过结构化知识库,实现科研经验的无缝传承。
快速检索类似反应,避免重复试错,缩短定位流程。在立项阶段即可洞察潜在的技术难点与机会。
秒级调取所有相关反应条件与原文,引用文献更无忧。让科研人员专注于逻辑构建而非繁琐的资料检索。
系统自动推荐可放大、可专利的可选反应路径。打通实验室到产业化的“最后一公里”,提升科研成果的商业价值。
参考反应查找时间 ↓
重复查文献时间 ↓
历史数据结构化留存
产业化机会寻找效率 ↑
“卓越加速,数据保全,对对外合作时提供结构化数据集,大幅提升课题组专业度。”
问题:5 年累计 3000+ 反应,分散在 PDF 和学生笔记本中,查询困难。
结果:DeepExtract 两周内完成全量结构化,半年内基于系统发现 2 条可放大路线,目前正在与知名企业进行产业对接。
问题:文献调研耗时长,难以系统比较不同工艺路线的成本与安全性。
结果:建立内部反应知识库,项目立项调研周期缩短 30%,显著提升了研究决策的科学性与时效性。
 中国科学院上海药物研究所
中国科学院上海药物研究所
 临沂大学
临沂大学 复旦大学
复旦大学 山东航空学院
山东航空学院
 山东大学
山东大学 中国科学院上海有机化学研究所
中国科学院上海有机化学研究所
 沈阳药科大学
沈阳药科大学
 河北医科大学
河北医科大学
 济宁医学院
济宁医学院
 清华大学
清华大学 滁州学院
滁州学院 中国药科大学
中国药科大学
 西湖大学
西湖大学 青岛农业大学
青岛农业大学
 黑龙江大学
黑龙江大学
A:绝对安全。我们支持私有化部署在本地服务器或校内网,确保数据不出组/不出企业,符合实验室最高安全保密要求。
A:可以。我们专门设计了“低质量数据适配模式”,支持手写扫描件、低分辨率图谱以及各种非标准格式的表单识别。
A:侧重不同。ELN 侧重“记录现状”,而 DeepExtract 侧重“从已有文献/海量历史数据中挖掘深层价值”,两者是互补关系。

